詳細內容請參考引用來源官方網站
印象中應該是在 graylog 6.x 後,官方導入了資料節點概念
最早在先前的系統架構是 graylog + MongoDB + OpenSearch/Elasticsearch
如今已經變成是 graylog + MongoDB + Data Node (OpenSearch) - 疑怎麼看起來沒變
每日收容Log量在10GB以下建議架構

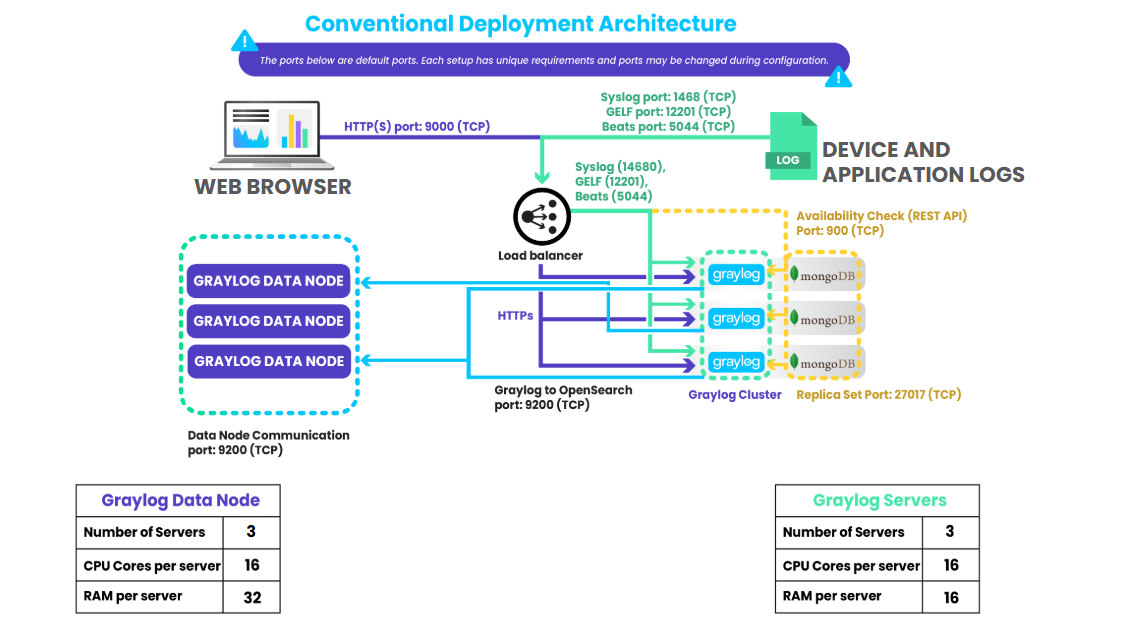
可以從架構圖中看出來建議部署的架構至少要2部以上,且官方的建議是要將 datanode 與 graylog 拆開建置
需要採哪種架構節點方式部署,官方也有指引可以評估每日需要收容的 log 量
每日收容Log量在100GB以下建議架構
多節點叢集部署架構示意圖
多節點叢集部署順序筆記
利用 Nginx 當做 Graylog 2個節點的負載平衡工具,建置 3個 MongoDB (其中 2個節點同時安裝 Graylog Server)及 3個 Datanode 於 nginx 設定檔中將 graylog 預計要收容的服務寫入設定檔中。 (/etc/nginx/nginx.conf)
stream {
upstream syslog_name1 {
server server_hostname1:port_number1;
server server_hostname2:port_number1;
}
server {
listen port_number1;
proxy_pass syslog_name1;
error_log /var/log/nginx/syslog_name1_error.log;
}
}
有關 http port 部分,如法炮製。 寫入設定檔中。(/etc/nginx/conf.d/default.conf)
upstream graylog {
server server_hostname1:9000;
server server_hostname2:9000;
}
server {
listen 80;
location / {
proxy_pass http://graylog;
}
}
依據官方的建置文件,安裝 MongoDB, Datanode 及 Graylog Server 後,採虛擬機的複製,將 guest OS 複製到指定的節點數量。
注意複製將會使得系統產生的 node-id 重複,確認節點數量複製完成後需停止服務刪除 /etc/graylog/server/node-id and /etc/graylog/datanode/node-id 後,重啟服務生成 node-id
MongoDB 群集設定及認證機制確認
Graylog JVM 調整
依據官方的建置文件,建議將 Graylog Server/Data Node 設定為主機配置記憶體大小的一半
Graylog 搜尋結果量大於預設60秒超時配置
vim /etc/graylog/server/server.conf Elasticsearch_socker_timeout = 60s